VidCRAFT3: Camera, Object, and Lighting Control for Image-to-Video Generation
Abstract
Controllable image-to-video (I2V) generation transforms a reference image into a coherent video guided by user-specified control signals. In content creation workflows, precise and simultaneous control over camera motion, object motion, and lighting direction enhances both accuracy and flexibility. However, existing approaches typically treat these control signals separately, largely due to the scarcity of datasets with high-quality joint annotations and mismatched control spaces across modalities. We present VidCRAFT3, a unified and flexible I2V framework that supports both independent and joint control over camera motion, object motion, and lighting direction by integrating three core components. Image2Cloud reconstructs a 3D point cloud from the reference image to enable precise camera motion control. ObjMotionNet encodes sparse object trajectories into multi-scale optical flow features to guide object motion. The Spatial Triple-Attention Transformer integrates lighting direction embeddings via parallel cross-attention. To address the scarcity of jointly annotated data, we curate the VideoLightingDirection (VLD) dataset of synthetic static-scene video clips with per-frame lighting-direction labels, and adopt a three-stage training strategy that enables robust learning without fully joint annotations. Extensive experiments show that VidCRAFT3 outperforms existing methods in control precision and visual coherence. Code and data will be released.
Methods
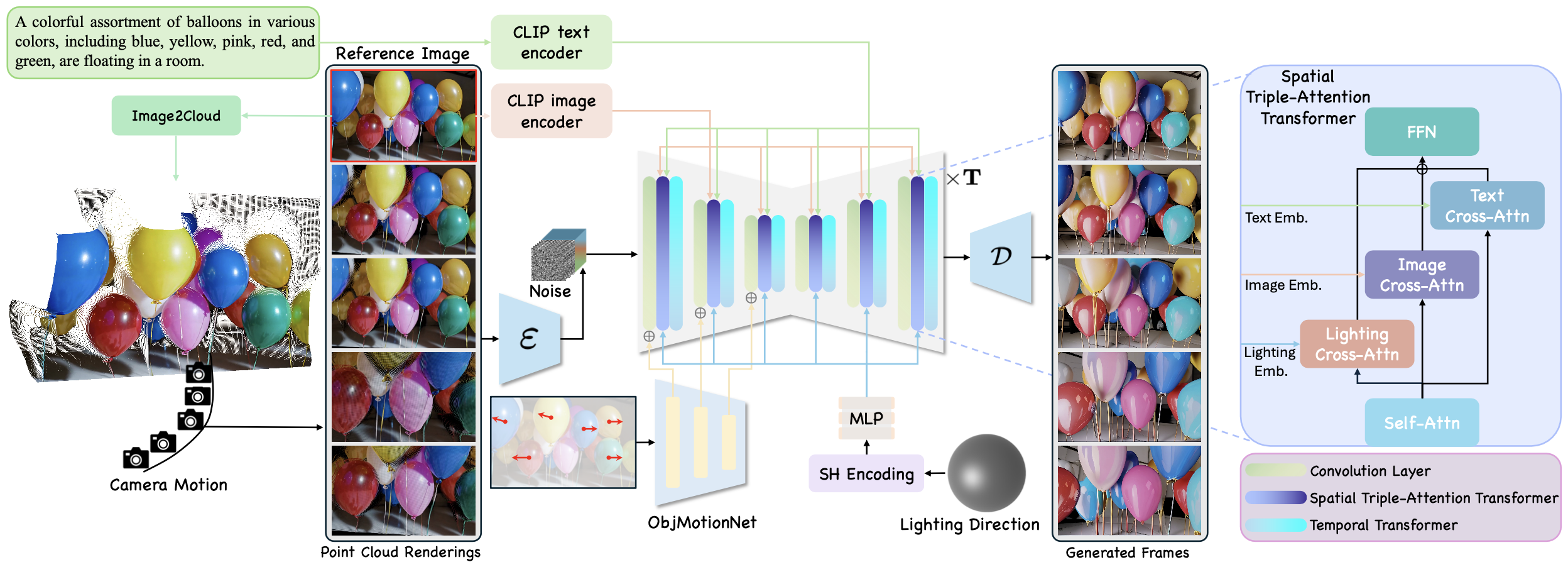
VidCRAFT3 builds on Video Diffusion Model (VDM) and consists of three main components: the Image2Cloud module generates high-quality 3D point cloud renderings from a reference image; the ObjMotionNet module encodes object motion represented by sparse trajectories, the output is integrated into the UNet encoder by element-wise addition; the Spatial Triple-Attention Transformer module integrates image, text, and lighting information via parallel cross-attention modules. The model generates video by conditioning on camera motion, object motion, and lighting direction, ensuring realistic and consistent outputs across different modalities.